题目背景
小 H 同学发现,他维护的存储系统经常出现有人用机器学习的训练数据把空间占满的问题,十分苦恼。
查找了一阵资料后,他想要在文件系统中开启配额限制,以便能够精确地限制大家在每个目录中最多能使用的空间。
文件系统概述
文件系统,是一种树形的文件组织和管理方式。在文件系统中,文件是指用名字标识的文件系统能够管理的基本对象,分为普通文件和目录文件两种,目录文件可以被简称为 目录。目录中有一种特殊的目录被叫做 根目录。
除了根目录外,其余的文件都有名字,称为文件名。合法的文件名是一个由若干数字([0-9])、大小写字母([A-Za-z])组成的非空字符串。普通文件中含有一定量的数据,占用存储空间;目录不占用存储空间。
文件和目录之间存在含于关系。上述概念满足下列性质:
- 有且仅有一个根目录;
- 对于除根目录以外的文件,都含于且恰好含于一个目录;
- 含于同一目录的文件,它们的文件名互不相同;
- 对于任意不是根目录的文件 ,若 不含于根目录,那么存在有限个目录 ,使得 含于 , 含于 ,, 含于根目录。
结合性质 4 和性质 2 可知,性质 4 中描述的有限多个目录,即诸 ,是唯一的。再结合性质 3,我们即可通过从根目录开始的一系列目录的序列,来唯一地指代一个文件。
我们记任意不是根目录且不含于根目录的文件 的文件名是 ,那么 的路径是:,其中符号 表示字符串的连接;对于含于根目录的文件 ,它的路径是:;根目录的路径是:。不符合上述规定的路径都是非法的。
例如: 是合法路径,但 、、、 都不是合法路径。
若文件 含于目录 ,我们也称 是 的孩子文件。 是 的双亲目录。我们称文件 是目录 的后代文件,如果满足:(1) 是 的孩子文件,或 (2) 含于 的后代文件。
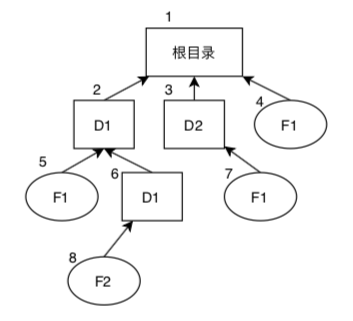
如图所示,该图中绘制的文件系统共有 8 个文件。其中,方形表示目录文件,圆形表示普通文件,它们之间的箭头表示含于关系。在表示文件的形状上的文字是其文件名;各个形状的左上方标记了序号,以便叙述。
在该文件系统中,文件 5 含于文件 2,文件 5 是文件 2 的孩子文件,文件 5 也是文件 2 的后代文件。文件 8 是文件 2 的后代文件,但不是文件 2 的孩子文件。文件 8 的路径是 。
配额概述
配额是指对文件系统中所含普通文件的总大小的限制。对于每个目录 ,都可以设定两个配额值:目录配额 和 后代配额。
我们称目录配额 是满足的,当且仅当 的孩子文件中,全部普通文件占用的存储空间之和不大于该配额值。我们称后代配额 是满足的,当且仅当 的后代文件中,全部普通文件占用的存储空间之和不大于该配额值。我们称文件系统的配额是满足的,当且仅当该文件系统中所有的配额都是满足的。
很显然,若文件系统中仅存在目录,不存在普通文件,那么该文件系统的配额一定是满足的。随着配额和文件的创建,某个操作会使文件系统的配额由满足变为不满足,这样的操作会被拒绝。例如:试图设定少于目前已有文件占用空间的配额值,或者试图创建超过配额值的文件。
题目描述
在本题中,假定初始状态下,文件系统仅包含根目录。你将会收到若干对文件系统的操作指令。对于每条指令,你需要判断该指令能否执行成功,对于能执行成功的指令,在成功执行该指令后,文件系统将会被相应地修改。对于不能执行成功的指令,文件系统将不会发生任何变化。你需要处理的指令如下:
创建普通文件
创建普通文件指令的格式如下:
C <file path> <file size>
创建普通文件的指令有两个参数,是空格分隔的字符串和一个正整数,分别表示需要创建的普通文件的路径和文件的大小。
对于该指令,若路径所指的文件已经存在,且也是普通文件的,则替换这个文件;若路径所指文件已经存在,但是目录文件的,则该指令不能执行成功。
当路径中的任何目录不存在时,应当尝试创建这些目录;若要创建的目录文件与已有的同一双亲目录下的孩子文件中的普通文件名称重复,则该指令不能执行成功。
另外,还需要确定在该指令的执行是否会使该文件系统的配额变为不满足,如果会发生这样的情况,则认为该指令不能执行成功,反之则认为该指令能执行成功。
移除文件
移除文件指令的格式如下:
R <file path>
移除文件的指令有一个参数,是字符串,表示要移除的文件的路径。
若该路径所指的文件不存在,则不进行任何操作。若该路径所指的文件是目录,则移除该目录及其所有后代文件。在上述过程中被移除的目录(如果有)上设置的配额值也被移除。
该指令始终认为能执行成功。
设置配额值
Q <file path> <LD> <LR>
设置配额值的指令有三个参数,是空格分隔的字符串和两个非负整数,分别表示需要设置配额值的目录的路径、目录配额和后代配额。
该指令表示对所指的目录文件,分别设置目录配额和后代配额。若路径所指的文件不存在,或者不是目录文件,则该指令执行不成功。
若在该目录上已经设置了配额,则将原配额值替换为指定的配额值。
特别地,若配额值为 0,则表示不对该项配额进行限制。若在应用新的配额值后,该文件系统配额变为不满足,那么该指令执行不成功。
输入格式
从标准输入读入数据。
输入的第一行包含一个正整数 ,表示需要处理的指令条数。
输入接下来会有 行,每一行一个指令。指令的格式符合前述要求。
输入数据保证:对于所有指令,输入的路径是合法路径;对于创建普通文件和移除文件指令,输入的路径不指向根目录。
输出格式
输出到标准输出。
输出共有 行,表示相应的操作指令是否执行成功。若成功执行,则输出字母 Y;否则输出 N。
样例解释
样例1
输入总共有 10 条指令。
其中前两条指令可以正常创建两个普通文件。
第三条指令试图创建 /A/B/1/3,但是 /A/B/1 已经存在,且不是目录,而是普通文件,不能再进一步创建孩子文件,因此执行不成功。
第四条指令试图创建 /A,但是 /A 已经存在,且是目录,因此执行不成功。
第五条指令试图删除 /A/B/1/3,由于该文件不存在,因此不对文件系统进行修改,但是仍然认为执行成功。
第六条指令试图在根目录增加后代配额限制,但此时,文件系统中的文件总大小是 2048,因此该限制无法生效,执行不成功。
第七条指令试图创建文件 /A/B/1,由于 /A/B/1 已经存在,且是普通文件,因此该指令实际效果是
将原有的该文件替换。此时文件总大小是 1124,因此第八条指令就可以执行成功了。
第九条指令递归删除了 /A/B 目录和它的所有后代文件。此时文件系统中已经没有普通文件,因此第十条命令可以执行成功。
样例2
输入共有 9 条指令。
第一条指令试图为 /A/B 创建配额规则,然而该目录并不存在,因此执行不成功。
接下来的两条指令创建了两个普通文件。
再接下来的两条指令分别在目录 /A/B 和 /A/C 创建了两个配额规则。其中前者是目录配额,后者是后代配额。
接下来的两条指令,创建了两个文件。其中,/A/B/3 超出了在 /A/B 的目录配额,因此执行不成功;但 /A/B/D/3 不受目录配额限制,因此执行成功。
最后两条指令,创建了两个文件。虽然在 /A/C 没有目录配额限制,但是无论是 /A/C 下的孩子文件还是后代文件,都受到后代配额的限制,因此两条指令执行都不成功。
子任务
本题目各个测试点的数据规模如下:

表格中,目录层次是指各指令中出现的路径中,/ 字符的数目。
所有输入的数字均不超过 。
测试用例
1
输入
10
C /A/B/1 1024
C /A/B/2 1024
C /A/B/1/3 1024
C /A 1024
R /A/B/1/3
Q / 0 1500
C /A/B/1 100
Q / 0 1500
R /A/B
Q / 0 1
输出
Y
Y
N
N
Y
N
Y
Y
Y
Y
2
输入
9
Q /A/B 1030 2060
C /A/B/1 1024
C /A/C/1 1024
Q /A/B 1024 0
Q /A/C 0 1024
C /A/B/3 1024
C /A/B/D/3 1024
C /A/C/4 1024
C /A/C/D/4 1024
输出
N
Y
Y
Y
Y
N
Y
N
N
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
vector<string> split(string& path) {
vector<string> v;
stringstream ss(path);
string s;
while (getline(ss, s, '/'))
v.emplace_back(s);
return v;
}
struct file {
bool isDir;
ll LD, LR;
ll SD, SR;
map<string, file> children;
ll fileSize;
file() {
isDir = true;
LD = LR = 1e18;
SD = SR = 0;
fileSize = 0;
}
};
file root;
vector<file*> findFile(vector<string>& fileNames) {
vector<file*> res;
res.push_back(&root);
for (int i = 1; i < fileNames.size(); i++) {
if (!res.back()->isDir)
break;
if (res.back()->children.count(fileNames[i]) == 0)
break;
res.push_back(&res.back()->children[fileNames[i]]);
}
return res;
}
bool create() {
string path;
ll fileSize;
cin >> path >> fileSize;
ll inc;
vector<string> fileNames = split(path);
vector<file*> filePtrs = findFile(fileNames);
if (filePtrs.size() == fileNames.size()) {
if (filePtrs.back()->isDir)
return false;
else
inc = fileSize - filePtrs.back()->fileSize;
} else {
if (!filePtrs.back()->isDir)
return false;
else
inc = fileSize;
}
for (int i = 0; i < filePtrs.size(); i++) {
if (filePtrs[i]->SR + inc > filePtrs[i]->LR)
return false;
if (i == fileNames.size() - 2)
if (filePtrs[i]->SD + inc > filePtrs[i]->LD)
return false;
}
for (int i = filePtrs.size(); i < fileNames.size(); i++)
filePtrs.push_back(&filePtrs.back()->children[fileNames[i]]);
filePtrs.back()->fileSize = fileSize;
filePtrs.back()->isDir = false;
for (auto& i : filePtrs)
i->SR += inc;
filePtrs.end()[-2]->SD += inc;
return true;
}
bool remove() {
string path;
cin >> path;
vector<string> fileNames = split(path);
vector<file*> filePtrs = findFile(fileNames);
if (filePtrs.size() != fileNames.size())
return true;
if (filePtrs.back()->isDir) {
for (auto& i : filePtrs)
i->SR -= filePtrs.back()->SR;
} else {
for (auto& i : filePtrs)
i->SR -= filePtrs.back()->fileSize;
filePtrs.end()[-2]->SD -= filePtrs.back()->fileSize;
}
filePtrs.end()[-2]->children.erase(fileNames.back());
return true;
}
bool quota() {
string path;
ll LD, LR;
cin >> path >> LD >> LR;
LD = (LD == 0 ? 1e18 : LD);
LR = (LR == 0 ? 1e18 : LR);
vector<string> fileNames = split(path);
vector<file*> filePtrs = findFile(fileNames);
if (filePtrs.size() != fileNames.size())
return false;
if (!filePtrs.back()->isDir)
return false;
if (filePtrs.back()->SD > LD || filePtrs.back()->SR > LR)
return false;
filePtrs.back()->LD = LD;
filePtrs.back()->LR = LR;
return true;
}
int main() {
int n;
cin >> n;
while (n--) {
string op;
cin >> op;
bool res;
if (op == "C")
res = create();
else if (op == "R")
res = remove();
else if (op == "Q")
res = quota();
cout << (res ? "Y\n" : "N\n");
}
}